Culture Hack Scotland 2011
Last weekend I attended Culture Hack Scotland, a fantastic hack day organised by the fine people at festivalslab. The range of data available was impressive, and the quality of the work produced by those attending was phenomenal. Congratulations to Rohan Gunatillake and Ben Werdmuller for a superb event.
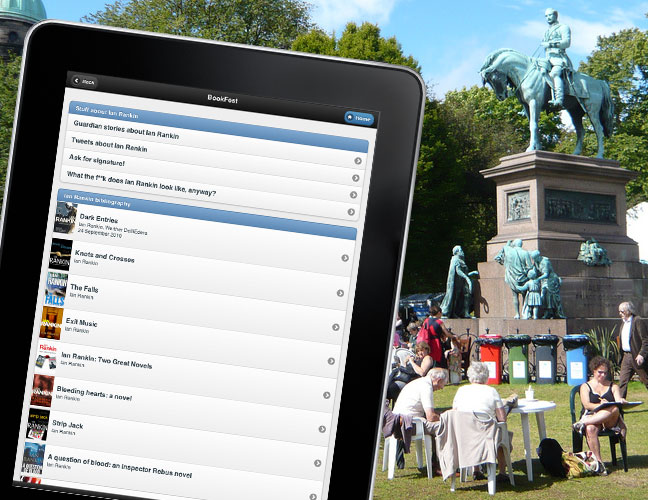
For my own hack, I decided to focus on the Edinburgh International Book Festival, which I thought might be neglected somewhat given the richness of the Edinburgh Fringe data available, and the fact that it didn’t have its own dedicated data sets. I wanted to produce a resource for people such as myself who seem to be afflicted by a gnawing insecurity of their own cultural viability. I greatly enjoy books, but I am by no means literary. I read plenty, but I don’t take a great interest in the authors themselves. When attending a book event, the author becomes the centre of focus, and so I wanted to produce a tool that would help attendees discover more about the creators of the books that they have been enjoying.
The result of this is BookFest, a mobile application for discovering more about the authors at The Edinburgh International Book Festival. The code is available for mockery, forkery and hackery on GitHub.
Data sources
The listings data for the Book Festival are taken from the 2010 Festival Listings API created by Ben Werdmuller specifically for Culture Hack Scotland. festivalslab are planning on having a live API for the 2011 festivals which I am very much looking forward to.
The listings API provides only event titles and descriptions and does not provide a specific field for authors, so the Google Books Search API was used to get matching books based on the event title, and a list of unique authors of these books was collated. I then removed any authors that don’t appear in the title. This works pretty well for finding the actual authors for an event.
Once I had authors, I could then query the Google Books API again for a proper bibliography. I was hoping to be able to show Google Books previews inline in the app, but there simply are not that many available.
The rest of the hack was spent adding value, and yes, gimmicks. I used the Guardian Open Platform API to pull Guardian articles relating to or written by the author, added the inevitable Twitter search, and grabbed photos of the author from the Google Image Search API. The reason for the latter feature should be clear - few people really know what a particular author actually looks like. One weakness with this approach is that a search for David Mitchell finds a lot of pictures of TV’s David Mitchell, and very few of the David Mitchell that wrote Cloud Atlas and other brain-melting fiction stonkers.
My favourite feature of all is the signature facility. If you have forgotten to bring a book by the author and do not wish to buy another copy at the festival book store, you can simply ask them to scribble on your touch-enabled device. For this I used the demo of the Interact JavaScript library that consolidates mouse and touch events for different devices. Of course, this feature is ridiculous as there is really no way to get the signature where it should be - in a copy of the author’s book. For that, we will have to settle for Margaret Atwood’s LongPen device.
Technologies
The app is hosted on Heroku, and uses the Sinatra Ruby framework on the back-end. This uses the rest-client and google-book gems for making API requests. On the front end I have used jQuery Mobile, which provides a decent mobile-style UI framework and an Ajax page model to give the website a more native application feel. jQuery Mobile is still in alpha, and so some of the rendering and animation feels a little unfinished at the moment, but overall it’s useful for getting something working very quickly.
Check out BookFest at http://bookfest.heroku.com
